
¿Cuál es el mejor disco duro? ¿Qué marca me conviene? ¿Qué modelo necesito realmente? ¿Sustituye RAID a una copia de seguridad (Backup)? ¿ Disco duro mecánico, SSD o SSD Híbrido (SSDH)?
Cualquier disco duro, sea de la marca que sea, y sea de la gama que sea, puede fallar. La temperatura de funcionamiento, el uso intensivo y otros factores pueden afectar a la vida del disco duro. Aunque un estudio publicado en 2007 por Google concluye que no hay una correlación sólida entre temperatura o intensidad de uso y la tasa de errores.
“Mean Time Between Failures” (MTBF)
MTBF es un término estadístico en relación a la fiabilidad como se expresa en horas de encendido (POH) y es a menudo una especificación asociada con los mecanismos de disco duro.
Pero vayamos un poco más allá con el MTBF de un disco duro. Disco MTBF es una estadística calculada, medición pre-producción . La palabra clave aquí es “PRE“, es decir que esto no es una estadística probada en real. Esta es una posibilidad estadística de que el tiempo que un dispositivo de disco va a durar.
Seagate ya no utiliza el estándar de la industria “Tiempo medio entre fallos” (MTBF) para cuantificar las tasas promedio de unidades de disco falla. MTBF ha demostrado ser útil en el pasado, pero es errónea.
Para hacer frente a cuestiones de fiabilidad, Seagate está cambiando a otro nivel: “Porcentaje de errores anual” (AFR).
Nuevo estándar de Seagate es AFR. AFR es similar a MTBF y sólo difiere en unidades. Mientras MTBF es el número probable promedio de horas de servicio entre fallos, AFR es el porcentaje probable de fallas por año, con base en el número total del fabricante de unidades instaladas de tipo similar. AFR es una estimación del porcentaje de productos que pueden fallar en el campo debido a una causa proveedor en un año. Seagate ha pasado de medidas promedio de las medidas porcentuales.
S.M.A.R.T.
La tecnología S.M.A.R.T. acrónimo de Self Monitoring Analysis and Reporting Technology consiste en la capacidad de detección de fallos del disco duro. La detección con anticipación de los fallos en la superficie permite al usuario el poder realizar una copia de su contenido, o reemplazar el disco, antes de que se produzca una pérdida de datos irrecuperable.
La tecnología S.M.A.R.T. monitoriza los diferentes parámetros del disco como pueden ser: la velocidad de los platos del disco, sectores defectuosos, errores de calibración, CRC, distancias medias entre el cabezal y el plato, temperatura del disco, etc.
-
Temperatura del disco: El aumento de la temperatura a menudo es señal de problemas de motor del disco.
-
Velocidad de lectura de datos: Reducción en la tasa de transferencia de la unidad puede ser señal diversos problemas internos.
-
Tiempo de partida (spin-up):Cambios en el tiempo de partida pueden reflejar problemas con el motor del disco.
-
Contador de sectores reasignados: La unidad Reasigna muchos sectores internos debido a los errores detectados, esto puede significar que la unidad va a fallar definitivamente.
-
Velocidad de búsqueda (Seek time)
-
Altura de Vuelo del Cabezal: La tendencia a la baja en altura de vuelo a menudo presagian un accidente del cabezal.
En Linux podemos usar smartmontools (smart monitoring tools) y en Windows CrystalDiskInfo.
ID/Hex Atributo Descripción 1/01 Raw Read Error Rate Frecuencia de errores en una lectura RAW desde disco. 2/02 Throughput performance Eficiencia media del disco duro. 3/03 Spin up time Tiempo necesario para girar. 4/04 Start/Stop count Número de inicios y paradas del eje del disco. 5/05 Reallocated sector count Cantidad de sectores remapeados por defectos. 6/06 Read channel margin Reserva de canales en operaciones de lectura. 7/07 Seek error rate Frecuencia de errores en posicionamiento. 8/08 Seek timer performance Eficiencia media de operaciones de posicionamiento. 9/09 Power-on hours count Número de horas transcurridas en funcionamiento. 10/0A Spin retry count Número de intentos de giro. 11/0B Calibration retry count Número de intentos de calibración del dispositivo. 12/0C Power cycle count Número de eventos de encendido. 13/0D Soft read error rate Frecuencia de errores de lectura vía software. 191/BF G-sense error rate Frecuencia de errores como resultado de impactos internos. 192/C0 Power-off retract count Número de eventos de apagado. 193/C1 Load/Unload cycle count Número de ciclos Load/Unload. 194/C2 HDA temperatura Informativo. Muestra la temperatura del disco. 195/C3 Hardware ECC recovered Número de errores recuperados on-the-fly (En discos MAXTOR). 196/C4 Reallocation count Número de operaciones de remapeado. 197/C5 Current pending sector count Número de sectores inestables (esperando por remapeado). 198/C6 Offline scan uncorrectable count Número de errores sin corregir. 199/C7 UDMA CRC error rate Número de errores de CRC durante modo UltraDMA. 200/C8 Write error rate Frecuencia de errores en operaciones de escritura. 201/C9 Soft read error rate Número de errores al intentar acceder a la pista siguiente. 202/CA Data Address Mark errors Número de errores de Marca de datos (DAM). 203/CB Run out cancel Número de errores de detección de memoria. 204/CC Soft ECC correction Número de errores corregidos por un software de detección de errores. 205/CD Thermal asperity rate (TAR) Número de errores de temperatura. 206/CE Flying height Altura de las cabezas sobre la superficie del disco. 207/CF Spin high current Cantidad más alta actual para girar el dispositivo. 208/D0 Spin buzz Número de rutinas para girar el dispositivo. 209/D1 Offline seek performance Rendimiento de búsqueda durante operaciones de apagado. 220/DC Disk shift Cambio de disco. 221/DD G-sense error rate Número de errores como resultado de impactos detectados. 222/DE Loaded hours Número de horas en estado operacional. 223/DF Load/unload retry count Carga causada por operaciones de recurrencia (lectura, grabación, posicionamiento, …). 224/E0 Load friction Carga causada por la fricción mecánica. 225/E1 Load/Unload cycle count Número total de ciclos de carga. 226/E2 Load-in time Tiempo de carga en disco. 227/E3 Torque amplification count Cantidad de rotaciones. 228/E4 Power-off retract count Número de eventos de apagado. 230/E6 GMR head amplitude Amplitud de las cabezas (GMR-head). 231/E7 Temperature Temperatura de la unidad. 240/F0 Head flying hours Tiempo transcurrido en operaciones de posicionamiento. 250/FA Read error retry rate Número de errores en operaciones de lectura.
Marcas y modelos, Gamas de discos duros (HDD)
Western Digital (WD)
Desktop – Escritorio (PC/MAC)
Caviar
- Green – Bajo Consumo – Sin tanto rendimiento (más lento), menos temperatura y más silencioso. 5400 rpm. 3 años garantía
- Blue – Mejor relación consumo/rendimiento, una mezcla de Green/Black. Consumo y ruido intermedio. 3 años garantía
- Black – Máximo rendimiento – un poco más de temperatura, y ruido. 7200 rpm. 5 años garantía
- Scorpio (portátiles)
- WD Purple – 5.400rpm Discos duros optimizados y pensados para monitorización y vigilancia (videovigilancia, cámaras de grabación continua, funcionamiento 24×7.).
Nas
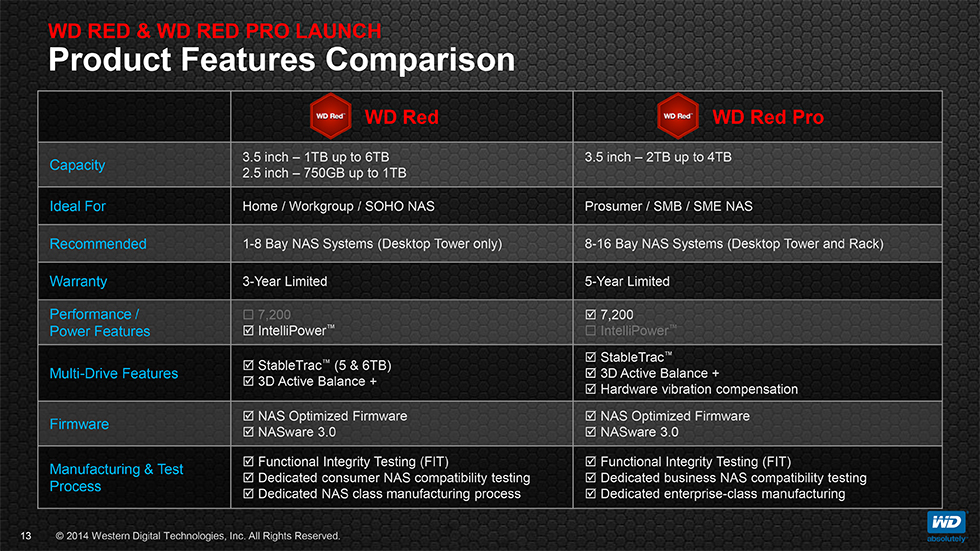
- Red – Entornos NAS (larga duración) 5.400rpm – Soporta RAID 0,1,5 (MTBF) de 1 millón de horas. 3 años de garantía
- WD Red Pro – Igual que los Red pero funcionan a 7.200rpm – 5 años de garantía
Enterprise – Uso empresarial – profesional – Datacenter
- WD Gold – Discos de altas prestaciones para centro de datos. Para servidores de alta disponibilidad. MTBF de 2,5 millones de horas.
- RE (Raid Edition RE2/RE3/RE4 (Enterprise) MTBF hasta 2 millones horas – 5 años de garantía
- SE Almacenamiento de gran capacidad y rendimientooptimizado para las aplicaciones de intensidad media.
- AE El disco duro de máxima capacidad y eficiencia energética para el almacenamiento en frío.
- Velociraptor – Alto rendimiento – 10.000 rpm. 5 años garantía
Seagate
Recordemos Seagate compró hace ya bastantes años, concretamente a finales del año 2005, la empresa Maxtor.
Desktop – Escritorio
- Barracuda – 7200.11 series, 7200.12, 7200.14
- Momentus (Portátiles) XT (Híbrido HDD SSD)
Enterprise – Uso empresarial
- Constellation ES – AFR 0.62%, 7.200 rpm, 1,4 millones MTBF, 5 años de garantía.
- Constellation CS – AFR 0.62%, 7.200 rpm, 3 años de garantía.
- Cheetah – 15.000 rpm SCSI
- Savvio – 15.000 rpm, AFR del 0,44%.
Hitachi
Hitachi compró la divisón de discos duros de IBM.
Western Digital (WD) compró Hitachi en el año 2011.
Desktop – Escritorio
- Deskstar – 7,200 rpm, 3 años de garantía.
Enterprise – Uso empresarial
- Ulatrastar – 15.000 rpm. 2 millones de horas de MTBF, 5 años de garantía
Samsung
Seagate compró en el año 2011 la división de discos duros de Samsung, así que los “Samsung Spin Point” son en realidad Seagate Barracuda.
Desktop – Escritorio
- Ecogreen
- Spinpoint F4
Toshiba – Fujitsu
Toshiba compró Fujitsu en el año 2009.
Enterprise – Uso empresarial
- Enterprise – 15k-10k rpm
Dell
Enterprise – Uso empresarial
- Enterprise – SAS: 10K & 15K
Hace unos años (2010) Western Digital (WD) decidió quitar del firmware la opción “Time Limited Error Recovery” (TLER) de la serie “Black” con lo que actualmente no son discos duros recomendados para hacer RAID.
Todos los discos duros de Western Digital se pueden colocar en un array RAID, pero no todos ellos admiten las característicasque las unidades RE (RAID Edition) son capaces y de alguna manera, más aptas para la conexión con los controladores RAID, ya sea completo hardware tarjetas adicionales (Adaptec, LSI, Areca, PCIe Intel y HighPoint de gama más alta) o los controladores a bordo de firmware (como Intel ICHxR, SiliconImage y controladores Marvell), como el control de errores yrecuperación de los conductores dobles cabezal del motor.
TLER es “limitado en el tiempo de recuperación de error”, la versión de WD de Control de Error Recovery (Seagates y Samsung se llama CCLT Seagate Error recovery control (ERC) de Western Digital: time-limited error recovery (TLER), Samsung/Hitachi: command completion time limit (CCTL) , que en realidad sólo entra en juego cuando unaunidad del array se encuentra con un error al intentar leer o escribir en un sector / bloque / page / etc. Para los discos en un controlador RAID de hardware, el controlador tiene su propio nivel de recuperación de errores al intentar rectificar los conflictos entre el mismo archivo de / bloque / página / sector que se supone que es reflejada (en RAID 1) o se almacena en la paridad (RAID 5 ).



